

New Paper: Towards a science of AI agent reliability
Quantifying the capability-reliability gap


By Stephan Rabanser, Sayash Kapoor, Arvind Narayanan
Suppose you hear about a new AI agent for improving productivity — by making purchases, or writing code, or sending emails, or handling a customer on your behalf. Should you trust it? Can the agent do the job reliably enough? After all, there are many horror stories of agents going wrong.
Surprisingly, even though the lack of reliability of AI agents is well known, right now the AI industry doesn’t have good tools for measuring reliability, or even a good definition of reliability.
Arvind and Sayash have long been thinking about this. Last fall, we were joined by postdoctoral researcher Stephan Rabanser, whose PhD looked at the reliability question in simpler, more traditional AI systems. We recruited a few other independent researchers, and have released what we hope is a comprehensive measurement of reliability. Our draft paper is called Towards a Science of AI Agent Reliability.
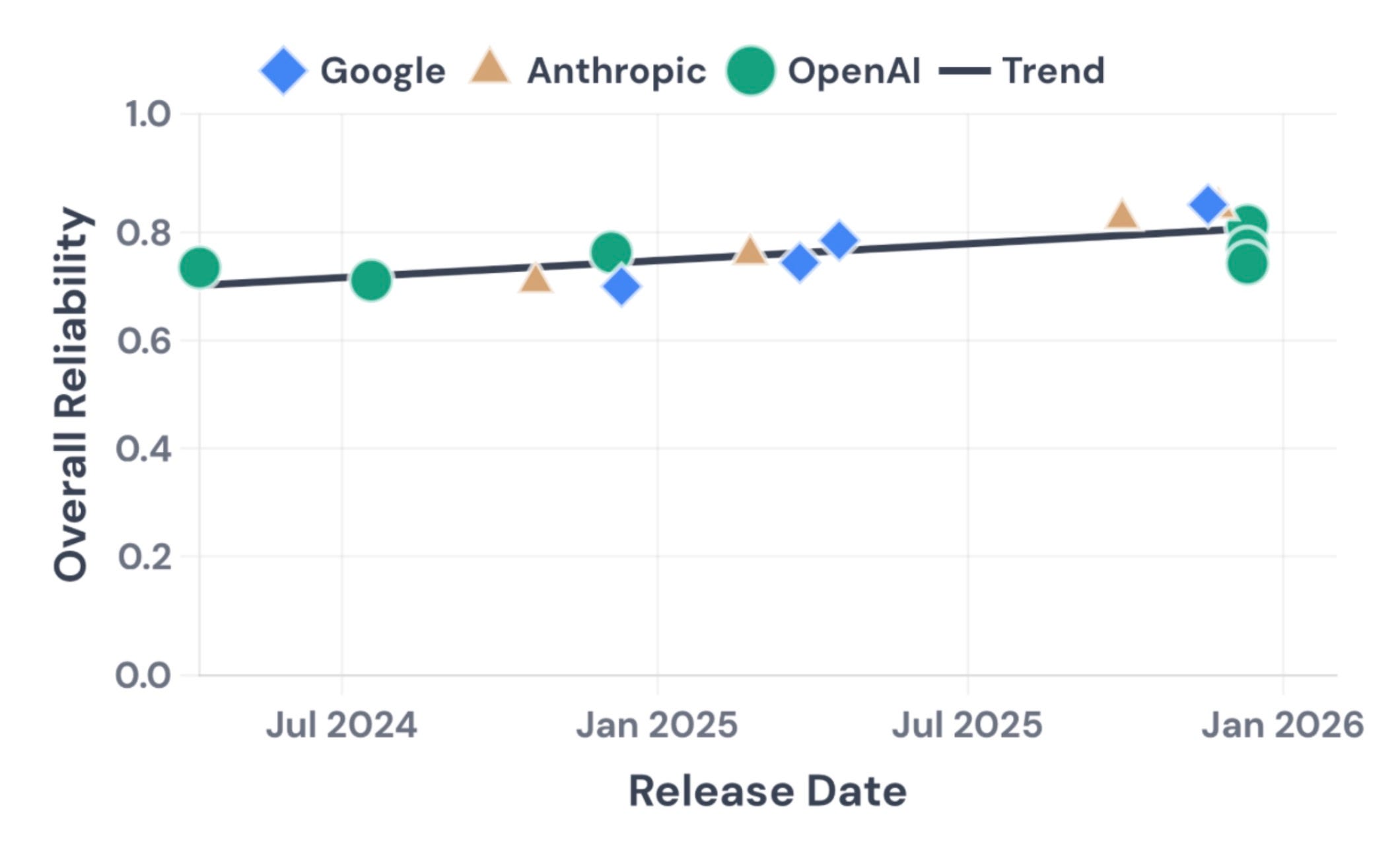
We borrowed insights from many other fields, such as nuclear and aviation safety. We were able to decompose reliability into 12 different dimensions. Evaluating 14 models on two complementary benchmarks, we found that nearly two years of rapid capability progress have produced only modest reliability gains. See our interactive dashboard here.
While our findings are tentative at this stage, we hope they can help explain the puzzlement among many in the industry as to why the economic impacts of AI agents have been gradual, even though they are crushing capability benchmarks.1 To help the community track reliability systematically, we plan to launch an AI agent “reliability index”. We hope this will stimulate researchers and industry to invest effort into improving reliability.
Table of Contents
Accuracy isn’t enough: four dimensions of reliability
When we consider a coworker to be reliable, we don’t just mean that they get things right most of the time. We mean something richer:
They get it right consistently, not right today and wrong tomorrow on the same thing (Consistency)
They don’t fall apart when conditions aren’t perfect (Robustness)
They tell you when they’re unsure rather than confidently guessing (Calibration)
When they do mess up, their mistakes are more likely to be fixable than catastrophic (Safety)
Unfortunately, AI agents are evaluated based on a single number, the average success rate at the task. That number has been going up quickly on many tasks over the last two years, which is why there’s so much excitement about deploying agents.
Safety-critical engineering fields (aviation, nuclear, automotive) figured out decades ago that reliability is not the same as average performance. These fields independently converged on the above four dimensions: consistency, robustness, predictability, and safety (the frequency and severity of failures).
For example, nuclear reactor protection systems must respond identically every time conditions warrant shutdown. Automotive safety testing evaluates responses to sensor failures and adverse weather. Nuclear risk assessment models thousands of failure modes and quantifies their probabilities. Aviation targets one catastrophic error per billion flight hours.
Capability gains are rapid, but improvements in reliability are modest
We refined and decomposed these four high-level dimensions into twelve metrics. We then tested agents based on 14 models from OpenAI, Google, and Anthropic, spanning 18 months of releases. We looked at two complementary benchmarks: a general assistant benchmark (GAIA) and a customer service simulation benchmark (TauBench). We ran each task five times, with instructions paraphrased. We injected faults in the tools and environment to measure robustness to such failures, and elicited the agents’ confidence at having solved the task to measure calibration. In total, we executed 500 overall benchmark runs.
We found that reliability has improved only modestly over 18 months, while accuracy improved substantially. All three major providers cluster together, so this appears to be an industry-wide limitation (though there are some cases where Anthropic’s models outperform OpenAI’s and Google’s).
More specifically, we measured the following criteria:
Consistency: Agents that can solve a task often fail on repeated attempts under identical conditions. Many models have trouble giving a consistent answer, with outcome consistency scores ranging from 30% to 75% across the board.
Robustness: Most models handle genuine technical failures (server crashes, API timeouts) gracefully. But if we rephrase the instructions with the same semantic meaning, performance drops substantially.
Predictability: Agents are not good at knowing when they’re wrong. This is the weakest dimension across the board. When agents report confidence, it often carries little signal. On one benchmark, most models couldn’t distinguish their correct predictions from incorrect ones better than chance.
Safety: Recent models are noticeably better at avoiding constraint violations, though financial errors, such as incorrect charges, remain a common failure mode. We use safety narrowly to mean bounded harm when failures occur, not broader concerns like alignment. We are still iterating on how we measure safety, so we report it separately from the aggregate reliability score.
Impact of scaling: Bigger models aren’t uniformly more reliable. Scaling up improves some dimensions (calibration, robustness) but can hurt consistency. Larger models with richer behavioral repertoires sometimes show more run-to-run variability.
Why we could be wrong
Our view is that reliability lags capability, and that reliability will remain a barrier to deployment unless researchers and developers focus effort on improving reliability as a separate dimension from accuracy. There are three reasons why we could be wrong.
First, there is some subjectivity in our dimensions and metrics. We have tried to minimize this by grounding our analysis in existing engineering fields. And we finalized our list of metrics before performing experiments, in order to prevent our hypothesis about slow reliability progress from influencing our selection of metrics. Still, we welcome other researchers to suggest alternative ways to measure reliability, and emphasize that our findings are tentative at this stage.
Second, maybe reliability won’t matter if accuracy gets high enough. Our metrics are carefully crafted so that accuracy gains don’t automatically lead to reliability gains. Broadly speaking, accuracy is about the rate of failures while reliability is about the nature of failures. But if an agent is accurate 99% of the time, maybe we can tolerate 1% error even if it is completely unpredictable. We disagree. Our view is that for autonomous operation in high-stakes contexts, we need 3-5 “nines” of performance — 99.9% to 99.999% accuracy — in order for reliability to become a non-issue, and we don’t think LLM-based agents are on track to reach such a threshold. But time will tell.
Third, reliability progress being slower than accuracy doesn’t necessarily mean that it is slow in absolute terms. If we project the current linear trend forward, agents will reach 100% reliability in just three years! We don’t think a linear model makes sense, in part because we expect each order of magnitude decrease in unreliability (1-reliability) to be as hard as the previous one. That is, we expect the jump from 90 to 99% reliability to be about as hard as the jump from 99 to 99.9% reliability, and so on. But again, we just have to wait and see.
Suppose we’re right. There are important implications for deployers, researchers & developers, and for those tracking the pace of AI progress. Let’s discuss each in turn.
What should deployers do differently?
Clearly distinguish automation from augmentation. A coding assistant that occasionally suggests wrong variable names is annoying; an autonomous agent managing an industrial plant yielding highly variable output is unacceptable. The difference is whether the agent is used to augment a human’s creativity or directly make decisions. Augmentation tools (copilots, search assistants) get a reliability “discount” because someone reviews the output. In some augmentation use-cases, reliability might actually be undesirable. For example, a creative writing assistant that produces the same story every time would be terrible at its job.
Incidentally, how well agents collaborate with humans is woefully under-theorized and under-measured. There is some early work on evaluating human-LM interaction, but both efforts predate autonomous agents, and we are not aware of any equivalent work studying how agents collaborate with humans over multi-step tasks. Uplift studies offer one useful lens, but a broader agent-focused effort is overdue.
Consider reliability for making release decisions. For automation tools (unattended workflows, customer-facing bots), reliability is non-negotiable. Deployers should consider requiring reliability thresholds before moving from sandbox to production, the way aviation requires certification before service. There are many other practices to borrow from such domains, such as building an incident-reporting culture around agent failures.
While the metrics we have identified are broadly useful as a starting point for understanding reliability, deployers should build their own internal evaluations tailored to their specific context and datasets.
What should researchers and developers do differently?
Benchmarks drive progress in AI. A year and a half ago, our paper AI Agents that Matter showed there was a big gap between what agent benchmarks measured and what matters in practice. Our new paper shows that the gap persists. To fix this disconnect, both AI evaluation and AI development practices need to change course.
Measure reliability. The current approach of running a benchmark once and reporting the accuracy number is a shallow, superficial performance measure. It is comparable to stress-testing a car once in perfect weather and declaring it safe if it passes. When evaluating agents, we need to test them for multiple runs (testing for variance in outcomes), under different conditions (evaluating adaptability), and on an ongoing basis (re-test as models and environments change). We call for reporting reliability profiles alongside accuracy, not instead of it.
Understand and improve reliability. Our experiments suggest that consistency and predictability are the biggest gaps preventing models from being more reliable. Agent developers should consider improving these weak points explicitly, possibly via targeted optimization or improved scaffolding. In particular, agents should be able to recognize when they are likely to fail and say so, and recover gracefully when they do fail. More speculative ideas include agents that explore different strategies during development but follow a consistent execution plan when deployed, rather than solving the same task differently each time, simultaneously delivering the best of agents and workflows.
What do our findings mean for AI progress?
The capability-reliability gap could be one reason why we are not seeing any of the rapid labor-market effects that Artificial General Intelligence has been predicted to bring about. It is not the only one. A recent UK AISI report identified six barriers to AGI. However, the report discussed each at a high level.
Our paper can be seen as putting flesh on the bones of one of these barriers — reliability. None of the four dimensions we identify can be considered solved at this point in time, and only two of the individual metrics, shown in green in the figure, can be considered (tentatively) solved.
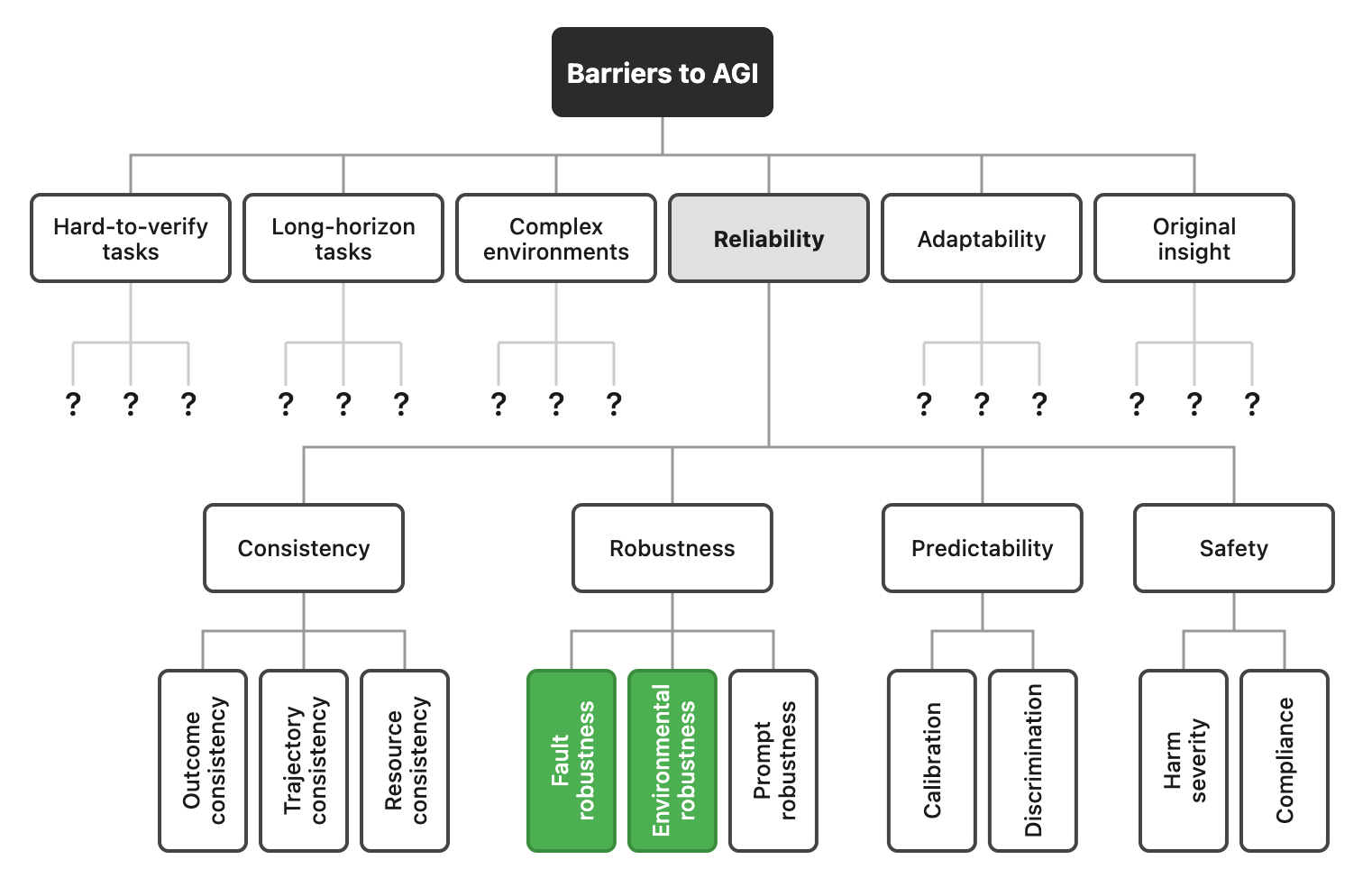
There is much work to be done in fleshing out the other barriers to AGI, analogous to our analysis of reliability. Our hunch is that this will reveal many other dimensions and metrics on which progress has been slow. The gazillion-dollar question is whether agents will get better across the board through general methods such as inference scaling and reinforcement learning, or whether painstaking work will be required to improve individual dimensions of reliability, adaptability, originality, and so on.
Further reading
The full 66-page paper is available on arXiv and includes definitions of the metrics we propose, details on our experimental setup, as well as an extended discussion on our recommendations and proposed future work. The authors are Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. Alongside the paper, we also provide an interactive dashboard of our results to enable practitioners to drill down into individual models, benchmarks, and reliability dimensions. The code to reproduce our experiments is available on GitHub.
This paper is part of our broader effort to advance the Science of AI Agent Evaluation. Key publications include AI Agents that Matter and Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation, recently accepted to ICLR 2026.
Our paper can be seen as building on work that aims to extend the scope of what we measure through benchmarks. For example, HELM introduced 7 metrics, including calibration and robustness, and used these to evaluate dozens of language models on prominent benchmarks.
Of course, this is not the only factor. Benchmarks continue to struggle with data contamination, so they might overestimate capability progress. AI as Normal Technology provides a useful framework to understand the barriers between capability progress and economic impacts. Reliability falls into the products/applications stage. Human, social, and organizational factors lie downstream. As a case study of how serious these can be, see our recent essay AI Won’t Automatically Make Legal Services Cheaper.
This is very helpful, thanks.
As someone who’s generally optimistic about the integration of AI for national security, this post should be “must reading” for everyone considering the rapid integration of frontier models (or most LLMs generally) into military or intelligence operations.
Absent the kind of oversight and governance capable of addressing each of the five critical criteria, the current “go fast and break things” attitude is fraught. To say the least.
I'm beginning to think more and more that viewing the current transformer-based LLM's as autonomously "agentic" is a category error. These tools are stateless, do not have internal boundaries, and are subject to vast variability due to the recursive nature of next-word prediction and the context window. They only way to make them reliable currently is through a lot of external limits, which are hard to build and fragile. The underlying ethos in our modern world of automating tasks to replace people for "efficiencies" sake doesn't work with this type of AI. Who really believes AI could do their own job? I get the sense that people making claims like this, are always assuming it's any other job than theirs. I'd like to see more emphasis on using current technology where it really belongs....augmentation.