

A guide to understanding AI as normal technology
And a big change for this newsletter


When we published AI as Normal Technology, the impact caught us off guard. It quickly became the most influential thing either of us had ever done.1 We took this as a strong signal to spend more of our time thinking and writing about the medium-term future of AI and its impacts, offering grounded analysis of a topic that tends to attract speculation. This is a shift in focus away from writing about the present-day and near-term impacts of AI, which is what the AI Snake Oil project was about.
Reflecting this shift, we have renamed this newsletter. We have already published two follow-up essays to AI as Normal Technology and will publish more regularly as we expand our framework into a book, which we plan to complete in late 2026 for publication in 2027.
Today, we address common points of confusion about AI as Normal Technology, try to make the original essay more approachable, and compare it to AI 2027.
Table of contents
Why it’s hard to find a “middle ground” between AI as Normal Technology and AI 2027
It is hard to understand one worldview when you’re committed to another
Reaping AI’s benefits will require hard work and painful choices
Normal doesn’t mean mundane or predictable
While the essay talks about what we mean by normal (more on that below), we could have been more explicit about what it doesn’t mean.
Our point is not “nothing to see here, move along”. Indeed, unpredictable societal effects have been a hallmark of powerful technologies ranging from automobiles to social media. This is because they are emergent effects of complex interactions between technology and people. They don’t tend to be predictable based on the logic of the technology alone. That’s why rejecting technological determinism is one of the core premises of the normal technology essay.
In the case of AI, specifically chatbots, we’re already seeing emergent societal effects. The prevalence of AI companions and some of the harmful effects of model sycophancy such as “AI psychosis” have taken most observers by surprise.2 On the other hand, many risks that were widely predicted to be imminent, such as AI being used to manipulate elections, have not materialized.
What the landscape of AI’s social impacts will look like in say 3-5 years — even based on the diffusion of current capabilities, not future capabilities — is anyone’s guess.
The development of technical capabilities is more predictable than AI’s social impacts. Daniel Kokotajlo, one of the authors of AI 2027, was previously famous in the AI safety community for his essay “What 2026 looks like” back in 2021. His predictions about the tech itself proved eerily accurate, but the predictions about social impacts were overall not directionally correct, a point he was gracious enough to concede in a podcast discussion with one of us.
All this makes AI a more serious challenge for institutions and policymakers because they will have to react nimbly to unforeseeable impacts instead of relying on the false comfort of prediction or trying to prevent all harm. Broadly speaking, the policymaking approach that enables such adaptability is called resilience, which is what our essay advocated for. But while we emphasized resilience as the approach to deal with potentially catastrophic risks, we should have been clearer that resilience also has an important role in dealing with more diffuse risks.
Perhaps the reason some readers misunderstood our view of predictability is the word “normal”. Again, our goal is not to trivialize the task of individually and collectively adapting to AI. In an ideal world, a better title would have been simply “AI as Technology”, but we didn’t think that that would effectively communicate that our goal is to provide an alternative to the exceptionalism that characterizes the superintelligence worldview which currently dominates the discourse.
A restatement of our thesis
If we were to extract and simplify the core of our thesis, it would be something like this:
There is a long causal chain between AI capability increases and societal impact. Benefits and risks are realized when AI is deployed, not when it is developed. This gives us (individuals, organizations, institutions, policymakers) many points of leverage for shaping those impacts. So we don’t have to fret as much about the speed of capability development; our efforts should focus more on the deployment stage both from the perspective of realizing AI’s benefits and responding to risks. All this is not just true of today’s AI, but even in the face of hypothetical developments such as self-improvement in AI capabilities. Many of the limits to the power of AI systems are (and should be) external to those systems, so that they cannot be overcome simply by having AI go off and improve its own technical design.
Aspects of this framework may have to be revised eventually, but that lies beyond the horizon bounding what we can meaningfully anticipate or prepare for:
The world we describe in Part II is one in which AI is far more advanced than it is today. We are not claiming that AI progress—or human progress—will stop at that point. What comes after it? We do not know. Consider this analogy: At the dawn of the first Industrial Revolution, it would have been useful to try to think about what an industrial world would look like and how to prepare for it, but it would have been futile to try to predict electricity or computers. Our exercise here is similar. Since we reject “fast takeoff” scenarios, we do not see it as necessary or useful to envision a world further ahead than we have attempted to. If and when the scenario we describe in Part II materializes, we will be able to better anticipate and prepare for whatever comes next.
Anyway, to reiterate, the core of the thesis is the underlying causal framework for understanding the relationship between AI and society, not any of the specific impacts that it might or might not have. In our view, if you share this causal understanding, you subscribe to the normal technology thesis. We have found that this framework is indeed widely shared, albeit implicitly.
That makes the thesis almost tautological in many readers’ minds. We are making what we see as — and what those readers should see as — a very weak claim! Not recognizing this causes readers to search for something much more specific that we may have meant by “normal”. But we didn’t. We aren’t classifying technologies as “normal” and “abnormal” and then putting AI into the “normal” bucket. We’re just saying we should treat AI like we treat other powerful general-purpose technologies.
This is not specific to large language models or any particular kind of AI. Incidentally, that’s why the title is “AI as normal technology” and not “AI as a normal technology”. Our views apply to the whole umbrella of technologies that are collectively referred to as AI, and other similar technologies even if they are not referred to as AI.
If our worldview is almost tautological, why bother to state it? Because it is in contrast to the superintelligence worldview. That’s the thing about worldviews: there can be mutually contradictory worldviews that each seem tautological to those who subscribe to them.
If disappointment about GPT-5 has nudged you towards AI as normal technology, it’s possible you don’t quite understand the thesis
It’s notable that there’s been a surge of interest in our essay after the release of GPT-5, and reasonable to surmise that at least some of that is because of people shifting their views a bit after being disappointed by the release.
This is strange! This isn’t the first time this has happened — we previously expressed skepticism of a big narrative shift around scaling that happened based on almost no new information. If a single update to one product shifts people’s views on the trajectory of AI, how reliable is people’s evidence base to begin with?
The reason why the normal technology framework predicts slow timelines is not because capabilities will hit a wall but because impacts will be slow and gradual even if capabilities continue to advance rapidly. So we don’t think disappointment with a new release should make you more sympathetic to viewing AI as normal technology. By the same token, a new breakthrough announced tomorrow shouldn’t cause you to be more skeptical of our views.
The best way to understand GPT-5 is that it’s a particularly good example of AI developers’ shift in emphasis from models to products, which we wrote about a year ago. The automatic model switcher is a big deal for everyday users of ChatGPT. It turns out that hardly anyone was using “thinking” models nearly a year after they were first released, and GPT-5 has bumped up their use dramatically.
In some communications Altman was clear that the emphasis for GPT-5 was usability, not a leap in capabilities, although this message was unfortunately undercut by the constant hype, leading to disappointment.
This broader shift in the industry is actually highly consistent with companies themselves (reluctantly) coming around to acknowledging the possibility that their path to success is to do the hard work of building products and fostering adoption, rather than racing to build AGI or superintelligence and count on it to sweep away any diffusion barriers. Ironically, in this narrative, GPT-5 is an example of a success, not a failure.
In fact, model developers are starting to go beyond developing more useful products (the second stage of our technology development & adoption framework) and working with deployers to ease early adoption pains (the third stage). For example, OpenAI’s Forward Deployed Engineers work with customers such as John Deere, and directly with farmers, on integrating and deploying capabilities such as providing personalized recommendations for pesticide application.
Why it’s hard to find a “middle ground” between AI as Normal Technology and AI 2027
Many people have tried to articulate middle ground positions between AI 2027 and AI as Normal Technology, perhaps viewing these as two ends of a spectrum of views.
This is surprisingly hard to do. Both AI 2027 and AI as Normal Technology are coherent worldviews. They represent very different causal understandings of how technology will impact society. If you try to mix and match, there is a risk that you end up with an internally inconsistent hodgepodge. (By the way, this means that if we end up being wrong, it is more likely that we will be wrong wholesale than slightly wrong.)
Besides, only in the Silicon Valley bubble can AI as Normal Technology be considered a skeptical view! We compare AI to electricity in the second sentence of the essay, and we make clear throughout that we expect it to have profound impacts. Our expectations for AI’s impact on labor seem to be at the more aggressive end of the range of expectations from economists who work on this topic.
In short, if you are looking for a moderate position, we encourage you to read the essay in full. Don’t let the title fool you into thinking we are AI skeptics. Perhaps you will conclude that AI as Normal Technology is already the middle ground you are looking for.
We realize that it can be discomfiting that the two most widely discussed frameworks for thinking about the future of AI are so radically different. (Our essay itself offers much commentary on this state of affairs in Part 4, which is about policy.) We can offer a few comforting thoughts:
We do have many areas of agreement with the AI 2027 authors. We are working on a joint statement outlining those areas. We are grateful to Nicholas Carlini for organizing this effort.
In our view, more important than agreement in beliefs are areas of common ground in policy despite differences in beliefs. Even relatively “easy” policy interventions that different sides can agree on will be a huge challenge in practice. If we can’t achieve these, there is little hope for the much more radical measures favored by those worried about imminent superintelligence.
There have been a few ongoing efforts to identify the cruxes of disagreement and agree on indicators that might help adjudicate between the two worldviews. We have participated in a few of these efforts and look forward to continuing to do so. We are grateful to the Golden Gate Institute for AI’s efforts on this front.
Speaking of developing indicators, we are in the process of expanding the vision for our project HAL, Holistic Agent Leaderboard. Currently it tries to be a better benchmark orchestration system for AI agents, but the new plan is to develop it into an early warning system that helps the AI community identify when AI agents have crossed capability thresholds for transformative real-world impacts in various domains.
We see these capability thresholds as necessary but not always sufficient conditions for impact, and as and when they are reached, they will much more acutely stress our theses about non-technological barriers to both benefits and risks.Note that HAL is not about prediction; it is about situational awareness of the present. This is a theme of our work. What is remarkable about the AI discourse in general, and us versus AI 2027 in particular, is the wide range of views not just about the future but about the things we can observe, such as the speed of diffusion (more on that below). Unless we as a community get much better at measurement of the present and testing competing causal explanations of progress, the level of energy directed at prediction will be misdirected, because we lack ways of resolving those predictions. For example, we’ve argued that we won’t necessarily know if “AGI” has been built even post facto. To some extent these limitations are intrinsic because of the lack of conceptual precision of ideas like AGI, but at the same time it’s true that we can do a lot better at measurement.
It is hard to understand one worldview when you’re committed to another
We wrote:
AI as normal technology is a worldview that stands in contrast to the worldview of AI as impending superintelligence. Worldviews are constituted by their assumptions, vocabulary, interpretations of evidence, epistemic tools, predictions, and (possibly) values. These factors reinforce each other and form a tight bundle within each worldview.
This makes communication across worldviews hard. For example, one question we often receive from the AI 2027 folks is what we think the world will look like in 2027. Well, pretty much like the world in 2025, we respond. They then push us to consider 2035 or 2045 or whatever year by which the world will be transformed, and they consider it a deficiency of our framework that we don’t provide concrete scenarios.
But this kind of scenario forecasting is only a meaningful activity within their worldview. We are concrete about the things we think we can be concrete about. At the same time, we emphasize the role of human, institutional, and political agency in making radically different futures possible — including AI 2027. Thus, AI as normal technology is as much a prescription as a prediction.
These communication difficulties are important to keep in mind when considering the response by Scott Alexander, one of the AI 2027 authors, to AI as Normal Technology. While we have no doubt that it is a good-faith effort at dialogue and we appreciate his putting in the time, unfortunately we feel that his response mostly talks past us. What he identifies as the cruxes of disagreement are quite different from what we consider the cruxes! For this reason, we won’t give a point-by-point response, since we will probably in turn end up talking past him in turn.
But we would be happy to engage in moderated conversations, a format with which we’ve had good success and have engaged in 8-10 times over the past year. The synchronous nature makes it much easier to understand each other. And the fact that the private conversation will be edited before making it public makes it easier to ask stupid questions as each side searches for understanding of the other’s point of view.
Anyway, here are a couple of important ways in which Alexander’s response talks past us. Recursive Self-Improvement (RSI) is a crux of disagreement for Alexander’s point of view, and he is surprised that it is barely worth a mention for us. In fairness we could have been much more explicit in our essay about what we think about RSI. In short, we don’t think RSI will lead to superintelligence because the external bottlenecks to building and deploying powerful AI systems cannot be overcome by improving their technical design. That is why we don’t discuss it much.3
Although it is not a crux for us, we do explain in the essay why we think the AI community is nowhere close to RSI. More recently we’ve been thinking about the fundamental research challenges that need to be solved, and there are a lot more than we’d realized. And it is worth keeping in mind that the AI community might be particularly bad at finding new paradigms for progress compared to other scientific communities. Again, this is an area where we hope that our project HAL can play a role in measuring progress.
Another topic where Alexander’s response talks past us is on the speed of diffusion, which we comment on briefly below and will address in more detail in a future essay.
The best illustration of the difficulty of discourse across worldviews is Alexander’s discussion of our hypotheses about whether or not superhuman AI abilities are possible in tasks such as prediction or persuasion. After reading his response several times, it is hard for us to figure out where exactly we agree and disagree. We wrote:
We think there are relatively few real-world cognitive tasks in which human limitations are so telling that AI is able to blow past human performance (as AI does in chess). ... Concretely, we propose two such areas: forecasting and persuasion. We predict that AI will not be able to meaningfully outperform trained humans (particularly teams of humans and especially if augmented with simple automated tools) at forecasting geopolitical events (say elections). We make the same prediction for the task of persuading people to act against their own self-interest.
You can read his full response to this in Section 3B of his essay, but in short it focuses on human biological limits:
Humans gained their abilities through thousands of years of evolution in the African savanna. There was no particular pressure in the savanna for “get exactly the highest Brier score possible in a forecasting contest”, and there is no particular reason to think humans achieved this. Indeed, if the evidence for human evolution for higher intelligence in the past 10,000 years in response to agriculture proves true, humans definitely didn’t reach the cosmic maximum on the African savannah. Why should we think this last, very short round of selection got it exactly right?
But rejecting a biological conception of human abilities is a key point of departure for us, something we take pains to describe in detail in the section “Human Ability Is Not Constrained by Biology”. That’s the problem with discussion across worldviews: If you take a specific statement, ignore the premises and terminological clarifications leading up to it, and interpret it in your worldview, it will seem like your opponent is clueless. Does Alexander think we are suggesting that if a savanna-dweller time traveled to the present, they would be able to predict elections?
He does emphasize that human performance is not fixed, but somehow sees this as a refutation of our thesis (rather than central to it). Perhaps the confusion arose because of our hypothesis that human performance at forecasting is close to the “irreducible error”. We don’t imply that the irreducible error of forecasting is a specific number that is fixed for all time. Of course it depends on the data that is available — better polling leads to better forecasting — and training that helps take advantage of increased data. And some of that training might even be the result of AI-enabled research on forecasting. We emphasize in our original essay that human intelligence is special not because of our biology, but because of our (contingent) mastery of our tools including AI. Thus, advances in AI will often improve human intelligence (abilities), and have the potential to improve the performance of both sides of the human-AI comparison we propose.
The point of our hypothesis is a simple one: We don’t think forecasting is like chess, where loads of computation can give AI a decisive speed advantage. The computational structure of forecasting is relatively straightforward, even though performance can be vastly improved through training and data. Thus, relatively simple computational tools in the hands of suitably trained teams of expert forecasters can squeeze (almost) all the juice there is to squeeze.
We are glad that Alexander’s response credits us with “putting their money where their mouth is on the possibility of mutual cooperation”. The sentiment is mutual. We look forward to continuing that cooperation, which we see as more productive than Substack rebuttals and counter-rebuttals.
Reaping AI’s benefits will require hard work and painful choices
There are two broad sets of implications of our framework: one for the economy and labor, and the other for safety. Once we get past a few basic premises (notably, that superintelligence is incoherent or impossible depending on how it is defined), our arguments behind these two sets of implications are largely different.
On economic impacts, our case is broadly that diffusion barriers won’t be overcome through capability improvement. As for safety, our case is primarily that achieving AI control without alignment is not only possible, it doesn’t even seem particularly hard, and doesn’t require scientific breakthroughs.
Since these two sets of arguments don’t overlap much, it is coherent to accept one set but not accept (or be ambivalent to) the other. Indeed, our view of the economic impacts seems to have resonated particularly strongly with readers. Since the essay’s publication, we have had many discussions with people responsible for AI strategy in various industries. We discovered that the way that they had been thinking about AI was consistent with ours, but they were starting to second-guess their approach because of all the hype. Our essay provided a coherent framework that backed up their intuitions as well as their observations in the trenches.4
While people deploying AI have a keen understanding of the difference between technology development and diffusion, our framework further divides each of those into two steps. On the development side, we emphasize the gap between models and products, or capabilities and applications. On the diffusion side, we differentiate between user learning curves and other aspects of adaptation by individuals, and the structural, organizational, or legal changes that might be necessary, which often require collective action. We illustrate the kinds of speed limits that operate at each of the four stages.
While user behaviors at least tend to change slowly but predictably, solving coordination problems or reforming sclerotic institutions — which are also prerequisites for effective technology adoption — are much more uncertain. As an example, consider how Air Traffic Control is stuck with technology from the middle of the 20th century despite the enormous costs of the lack of modernization becoming apparent.
While our essay pointed out that analogous diffusion barriers exist in the case of AI, we are only now doing the work of spelling out those barriers and identifying specific reforms that might be necessary. We will be writing more on this front, some of it in collaboration with Justin Curl.
It is worth bearing in mind that advanced AI is entering a world that is already both highly technological and highly regulated. We repeatedly find that the parts of workflows that AI tackles are unlikely to be bottlenecks, because much of the available productivity gains have already been unlocked through earlier waves of technologies. Meanwhile the actual bottlenecks prove resistant due to regulation or other external constraints. In many specific domains including legal services and scientific research, competitive dynamics are so strong that productivity gains from AI lead to escalation of arms races that don’t ultimately translate to societal value.
The surreal debate about the speed of diffusion
We’ve mentioned a few times that different camps disagree on how they characterize current AI impacts. Nowhere is this more apparent than the speed of diffusion. AI boosters believe that it is being adopted unprecedentedly rapidly. We completely disagree. Worse, as more evidence comes out, each side seems to be getting more certain of their interpretation.
We are working on an in-depth analysis of the speed of diffusion. For now, we point out a few basic fallacies in the common arguments and stats that get trotted out to justify the “rapid adoption” interpretation.
First, deployment is not diffusion. Often, when people talk about rapid adoption they just mean that when capabilities are developed, they can be near-instantly deployed to products (such as chatbots) that are used by hundreds of millions of users.
But this is not what diffusion means. It is not enough to know how many people have access to capabilities: What matters is how many people are actually using them, how long they are using them, and what they are using them for. When we drill down into those details, the picture looks very different.
For example, almost a year after the vaunted release of “thinking” models in ChatGPT, less than 1% of users used them on any given day! We find no pleasure in pointing this out even though it supports our thesis. As enthusiastic early adopters of AI, this kind of number is so low that it is hard for us to intuitively grasp, and frankly pretty depressing.
Another example of a misleading statistic relates to the fraction of workers in certain high-risk domains who use AI. Such statistics tend to be offered in service of the claim that AI is being rapidly adopted in risky ways. But even in high risk domains most tasks are actually mundane, and when we dig into the specific uses don’t seem that risky at all.
For example, a survey by the American Medical Association reported that a majority of doctors are using AI. But this includes things like transcription of dictated notes.5 It also includes things like asking a chatbot for a second opinion of a diagnosis (about 12% reported this use case in 2024, a whopping 1 percentage point increase from 11% in 2023). This is definitely a more serious use than transcription one, but it is still well-founded. As we’ve pointed out before, even unreliable AI is very helpful for error detection.
Increasing adoption of AI for these tasks does not mean that doctors are about to start YOLOing it and abdicating their responsibility to their patients by delegating their decisions to ChatGPT. The vast majority of doctors understand the difference between these two types of uses, and there are many overlapping guardrails preventing widespread irresponsible use in the medical profession, including malpractice liability, professional codes, and regulation of medical devices.
The most misleading “rapid adoption” meme of all might be this widely shared chart, showing that ChatGPT reached 100M users in about two months:
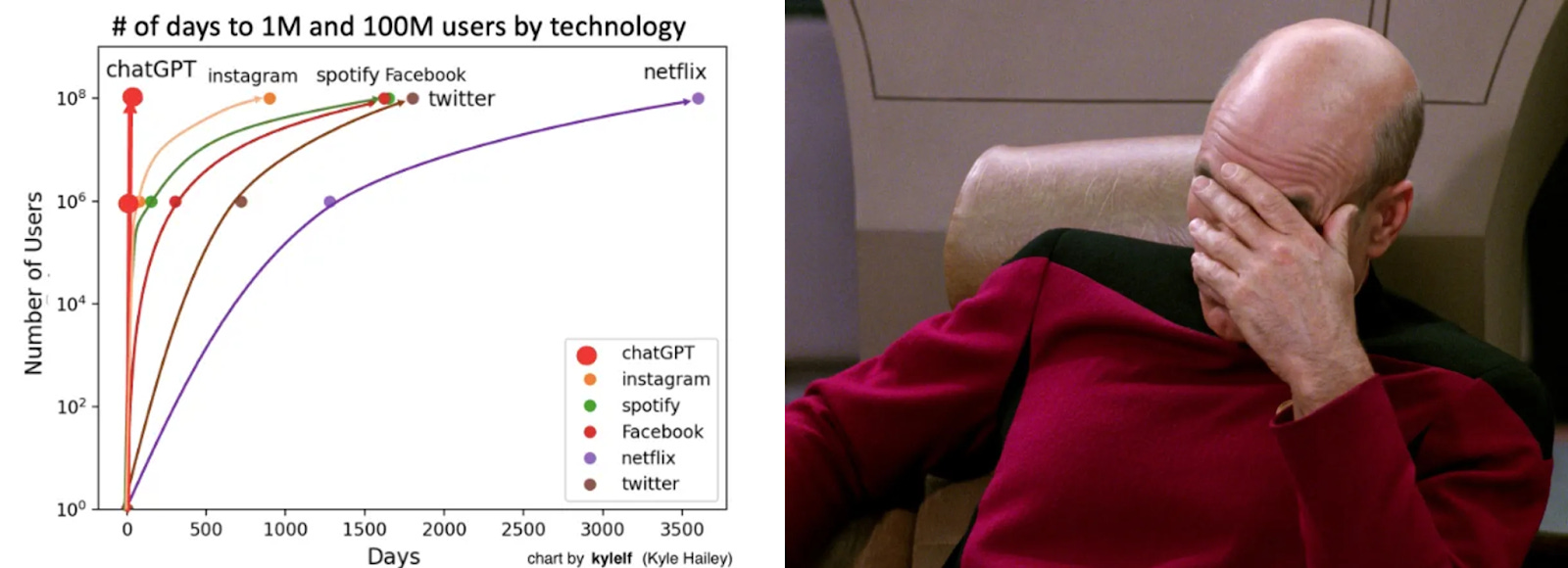
It compares ChatGPT user growth with (1) Instagram, Facebook, and Twitter, which are social media apps whose usefulness depends on network effects, and therefore characteristically grow much slower than apps that are useful from day one (2) Spotify, an app that was initially invite-only and (3) Netflix, a service that launched with a limited inventory and required a subscription to use.6
What is reflected in this chart are early adopters who will check out an app if there’s buzz around it, and there was deafening buzz around ChatGPT. Once you exhaust these curious early users, the growth curve looks very different. In fact, a year later, ChatGPT had apparently only grown from 100M to 200M users, which meant that the curve evidently bent sharply to the right. That is conveniently not captured in this graph which reflects only the first two months.
This chart would be useful if it gave us any evidence that the usual barriers to diffusion have been weakened or eliminated. It doesn’t. Two months is not enough time for the hard parts of diffusion to even get started, such as users adapting their workflows to productively incorporate AI. As such, this chart is irrelevant to any meaningful discussion of the speed of diffusion.
There are many other problems with this chart, but we’ll stop here.7 Again, this is far from a complete analysis of the speed of AI diffusion — that’s coming. For now, we’re just making the point that the majority of the commentary on this topic is simply unserious. And if this is what the discourse is like on a question for which we do have data, it is no surprise that predictions of the future from different camps bear no resemblance to each other.
Why AI adoption hits different
If the “rapid diffusion” meme is so wrong, why is it so pervasive and persistent? Because AI adoption feels like a tsunami in a way that the PC or the internet or social media never did. When people are intuitively convinced of something, they will be much less skeptical of data or charts that purport to confirm that feeling.
We recognize the feeling, of course. Our own lived experience of AI is different from past waves of technologies. Initially, we dismissed this as a cognitive bias. Whatever change we’re living through at the moment will feel like a much bigger shift than something we successfully adapted to in the past.
We now realize that we were wrong. The cognitive bias might be a small part of the explanation, but there is a genuine reason why AI adoption feels much more rapid and scary. In short, while it’s true that deployment is not diffusion, in the past, gradual deployment meant that users were somewhat buffered from having to constantly make decisions about adoption, but now that buffer has been swept away. Let’s explain with a comparison to internet adoption.
Those of us who adopted dial-up internet in the 90s will remember a story that went something like this. When we first heard about the tech, we were put off by the high price of a PC. Gradually those prices came down. Meanwhile we got some experience using the internet at work or at a friend’s house. So when we bought a PC and dialup internet a few years later, we already had some training. At first, dialup was slow and expensive and there weren’t even that many websites, so we didn’t use the internet that much. Gradually prices came down, bandwidth improved, and more content came online, and we learned how to use the internet productively and safely in tandem with our increasing use.
Adopting general-purpose AI tools in the 2020s is a radically different experience because deployment of new capabilities is instantaneous. People have to spend a much higher percentage of time evaluating whether to adopt AI for some particular use case, and are constantly being told that if they don’t adopt it they will be left behind.
All our earlier points stand — learning curves exist, human behavior takes a long time to change, and organizational change even longer. But not using AI is somewhat of an active choice, and people no longer have the excuse of not to think about it because they don’t yet have access.
In short, deployment is only one of many steps in diffusion, and removing that bottleneck probably made diffusion slightly faster. But it feels dramatically faster because as soon as one hears about a particular AI use case, one has to decide whether to adopt it or not, even if it is ultimately the case that the vast majority of the time, people are deciding not to, for various reasons that might be rational or irrational.
Concluding thoughts
One thing on which we definitely agree with AI boosters is that AI is not going away, nor will it become a niche like crypto that most people can ignore. Now that the collective initial shock of generative AI has worn off, there’s a need for structured ways to think about how AI’s impacts might unfold, instead of (over)reacting to each new technical capability or emergent social effect.
The AI-as-normal-technology framework — which we continue to elaborate in this newsletter — is one such approach. It is worth being familiar with, at least as an articulation of a historically grounded default way to think about tech’s societal impact, against which more exceptionalist accounts can be compared. The framework has some degree of actionable guidance for business leaders, workers, students, people concerned about AI safety or AI ethics, and policymakers, among others. We hope you follow along and contribute to the discussion.
We are grateful to Steve Newman and Felix Chen for feedback on a draft.
Further reading/viewing
Arvind presented the paper at the World Bank Development Conference, focusing on the economic and labor implications.
Arvind’s new YouTube channel discusses AI developments based on the normal technology perspective.
We were fortunate to receive press coverage for AI as Normal Technology:
In the last month, the New York Times had three op-eds that discussed the essay in depth, by Eric Schmidt and Selina Xu, by David Wallace-Wells, and by Ezra Klein.
Last week, the Economist discussed the normal technology thesis in the article "What if artificial intelligence is just a “normal” technology?"
In The New Yorker, Joshua Rothman contrasted AI 2027 with AI as Normal Technology.
In Prospect Magazine, Ethan Zuckerman discussed the utility of viewing AI as Normal Technology.
James O'Donnell, for the MIT Technology Review, summarized the AI as Normal Technology thesis.
Some of our podcast appearances include: Arvind on New York Times' Hard Fork, and Tim O’Reilly’s podcast; Sayash on Lawfare's Scaling Laws and Carnegie's Interpreting India.
We have had conversations with many people who have the superintelligence worldview, including many of the authors of AI 2027: Sayash debated Daniel Kokotajlo and Eli Lifland; Arvind debated Daniel Kokotajlo, and in Asterisk Mag, Arvind and Ajeya Cotra debated whether AI progress has a speed limit, and how we’d know.
As is so often the case, fortuitous timing played a big role in the success of the essay. It was released two weeks after AI 2027, but this was purely by coincidence — our publication date was actually based on the Knight Institute symposium on AI and Democratic Freedoms. We are grateful to the Institute for the opportunity to publish the essay.
Mental health issues with chatbots in general, and problems such as addiction, have been widely recognized and discussed, including in our book AI Snake Oil. These tend to be based on an analogy with social media. But it's one thing to anticipate the potential for mental health impacts, and another to predict specifically what impacts might emerge and how to avoid them.
That said, we acknowledge that our whole thesis might be wrong, and it is more likely that we’re wrong if RSI is achieved.
The framework is adapted from the classic diffusion-of-innovations theory and also influenced by recent writers such as Jeffrey Ding who have analyzed geopolitical competition in AI through the lens of the innovation-diffusion gap.
While there are risks even here, we think it is definitely an application that doctors should be exploring.
In fact, there have been other apps whose initial growth was as fast or faster than ChatGPT, such as Pokemon Go and Threads (which bootstrapped off of Instagram and thus wasn’t reliant on network effects). But again, our bigger point is that this type of comparison is not informative. Threads ended up being something of a dud despite that initial growth.
Frankly, the far more impressive stat in this graph, in our view, is Instagram getting to a million users in only 2.5 months despite the need for network effects — considering that it was back in 2010 when phone internet speeds were much lower, the app was iPhone only (!), and mainly spread among 18-34 year olds in the United States in the early days.
Your response to the AI 2027 folks' questions about what the world will look like in 2035, 2045, etc., is spot-on. It's also a handy go-to for some of the more vexing provocations from hypeists. As you say, "This kind of scenario forecasting is only a meaningful activity within their worldview. We are concrete about the things we think we can be concrete about." It's not disrespectful to point out a difference in premises, but when you do so, you're signaling that you won't play games on their terms.
This essay is a breath of fresh air in the AI discourse—grounded, insightful, and deeply pragmatic. I appreciate how you clarify that “normal technology” doesn’t mean “trivial,” but instead provides a constructive, resilience-focused framework for thinking about AI’s evolving impact. Thank you for bringing nuance and historical perspective back to the conversation. Looking forward to your continued work and the expanded book!